Exploring Apache Incubator: Podlings and the Apache Way
Ever heard of Kafka? Or Spark? A respectable data analyst or software engineer can not deny they missed these two data infrastructure services. Maybe you also know they originate from the same incubator company: Apache. Interestingly Apache incubator has much more on their list. In this article I will pick some of there recent projects and dive into their possibilities.
Apache incubator is part of the Apache Software Foundation (ASF). As most foundations, they have a astonishing credo, based on specific rules. Happy to share the one that got my attention the most: “Guiding podlings to govern and grow their community according to the Apache Way, the ASF’s philosophy and guidelines for collaborative development.” I have to be honest, I find it really impressive how such a community can be the foundation of so much technological progress. The Apache way is, according to their site, hard to define. Although they mention the following as highly important: Independence and Community over Code. No vendors are involved, e.g. no organisation. Its only individuals who drive the innovations. Secondly, when it comes to updating code that is not written well, you need a good community. If your community is bad, you code base will not develop and enhance. Hence, Community over Code. With all this in mind, I am excited to tell about three of their projects:
First on the list: Amoro
Amoro builds lake-native data warehouses based on multiple tools under which Spark. But what exactly is a lake-native data warehouse? It’s a data warehouse that builds on data lakes. Examples are Snowflake, Bigquery and Databricks. Amoro differs in being an open-source and it decouples from underlying infrastructure. Its AMS - Amoro management service - separates plug in computation engines like Flink, Spark and Trino from standardized interfaces such as Hive Metastore, S3 or Azure Blob. This makes it more flexible and easier to switch.
Second: Fluss
Fluss is the bridge between a data lake and real time streaming data. The servers of Fluss are specifically build for real time streaming data. According to their website site, it improves streaming performance 10 times using a columnar format. It also reduces costs and is open source, like Amoro. The difference between Apache Kafka and Fluss is that Kafka is build for movement of data and Fluss has the goal to enhance streamimg performance for analytics. So where Kafka moves data from A to B and Fluss uses the data to perform analytical queries. A Kafka and Fluss infrastructure meets best of both worlds. Combined with Apache Flink, which picks up data from Kafka, clears it and writes it to Fluss, it supports a comprehensive infrastructure for real time data.
Thirdly: Airflow
Enter, Airflow: this is a known term and is already present since 2016 (a lifetime within the techworld). Airflow has been graduated from the Apache incubator project in 2018 which not necessarily makes it the newest technology. It is software that supports data engineers with scheduling, monitoring and developing batch jobs. Its framework is python based and it includes a UI that helps to visualise your jobs. To me this shows the power of open-source tools in streamlining complex data workflows. See the following image for an impression of the UI:
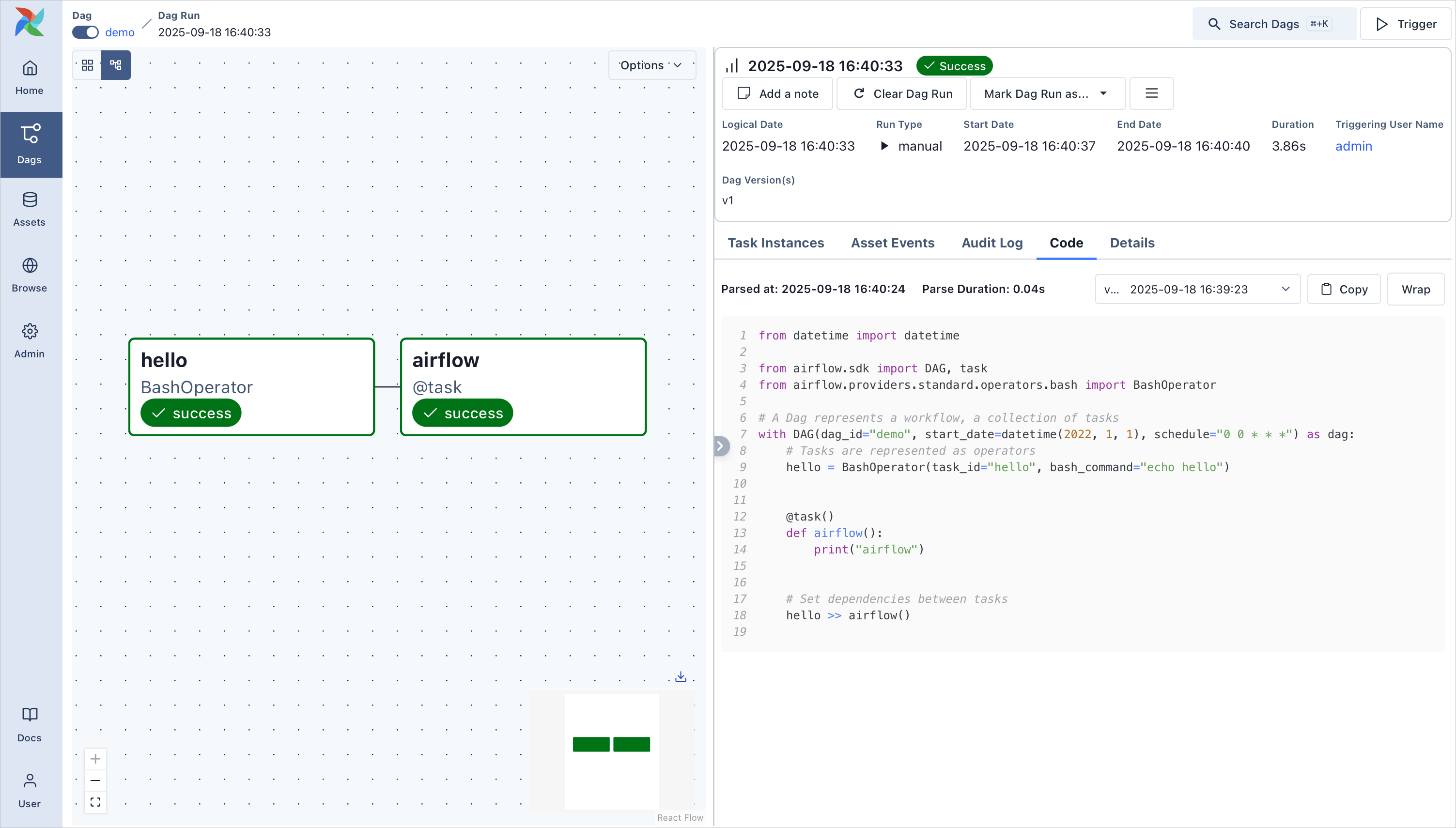
There’s still much to explore, with a long list of projects. Some names are familiar, but many are completely new to me. I’m glad to have stumbled upon this community and look forward to diving deeper into it. Let’s look at these podlings, because they could become as well known as Kafka and Spark are now already.
Do you want to read more? Please see the reference below:
Apache Software Foundation. (n.d.). Current Apache Incubator Projects. Apache Incubator.